This year’s Cassava Leaf detection challenge was a very good one as many more people participated compared to the last year where only 86 teams participated in comparison there were over 3500+ teams that took part this year. I joined this challenge a bit later. I am placed at 1444/3900 teams (top 38%). I missed the medal this time around but am pretty happy on surviving the shapeup which shot me up 425 places up the Leader board. I wish to note down everything that did in this competition and everything I learned this time around. It will be useful for me in the future to reference this as well as beginners getting into kaggle who have trouble how to approach a given problem. All the code is available as a Kaggle notebook here. So, Let’s begin.

Problem Statement Overview
As the second-largest provider of carbohydrates in Africa, cassava is a key food security crop grown by smallholder farmers because it can withstand harsh conditions. At least 80% of household farms in Sub-Saharan Africa grow this starchy root, but viral diseases are major sources of poor yields. With the help of data science, it may be possible to identify common diseases so they can be treated.
Existing methods of disease detection require farmers to solicit the help of government-funded agricultural experts to visually inspect and diagnose the plants. This suffers from being labor-intensive, low-supply, and costly. As an added challenge, effective solutions for farmers must perform well under significant constraints, since African farmers may only have access to mobile-quality cameras with low-bandwidth.
Existing methods of disease detection require farmers to solicit the help of government-funded agricultural experts to visually inspect and diagnose the plants. This suffers from being labor-intensive, low-supply, and costly. As an added challenge, effective solutions for farmers must perform well under significant constraints, since African farmers may only have access to mobile-quality cameras with low-bandwidth.
In this competition, we introduce a dataset of 21,367 labeled images collected during a regular survey in Uganda. Most images were crowdsourced from farmers taking photos of their gardens, and annotated by experts at the National Crops Resources Research Institute (NaCRRI) in collaboration with the AI lab at Makerere University, Kampala. This is in a format that most realistically represents what farmers would need to diagnose in real life.
Our task in this competition is to classify an image into any of the 5 categories:
- Cassava Bacterial Blight (CBB)
- Cassava Mosaic Disease (CMD)
- Cassava Brown Streak Disease (CBSD)
- Cassava Green Mottle (CGM)
- Healthy
My Approach To Solving The Problem
Now that we have an understanding of what the problem statement is, we know this is clearly a classification problem (multi-class). For classification, we can use many Machine learning models after converting each image into an array, but CNN’s are a better place to begin for images.
I tried using a simple CNN architecture that I use for every image classification problem, used random weights initialization, and used SGD with Nesterov momentum. (If you want to learn about Nesterov momentum go here ) This did not give me any good results.
The Flow of My Experiments
-
Did a little EDA on the data, to know what the class distribution was like.
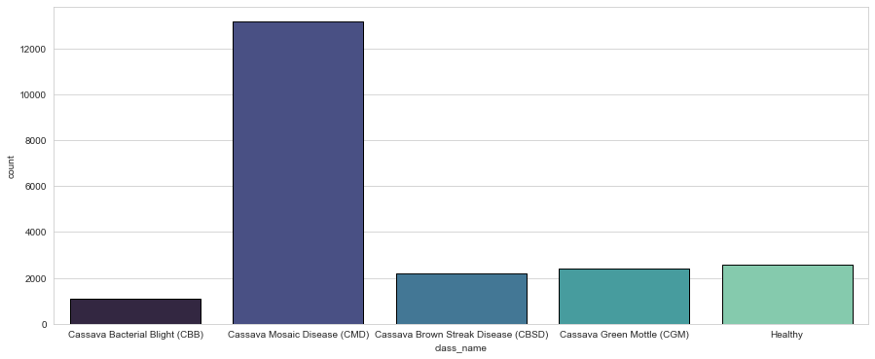
Key Insights :
- Cassava Mosaic Disease (CMD) is the dominant class in the training set constituting 61.5% of the total data
- The dataset is very skewed so there might be a need for upsampling or undersampling the images.
-
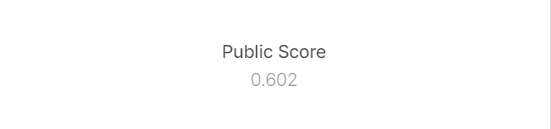
The training set was so skewed, I tested whether the test set (which was private, uploaded notebook will predict on the test set, that means we did not have any info on the test set), I uploaded a notebook which predicted everything to be the dominant class(CMD).Surprisingly, this gave an accuracy of 60.2%.
-
I first intended to not use K-Fold CV as it’s resource-intensive and kaggle puts a 9hr limit on a single session. I decided to use 10% of the data as a validation set and the remaining as the training set.
-
At first I used just little augmentations, but a few heavy augmentations goes a long way. I used the albumentations library to augment my images.
-
The modeling part was very tricky, as I have said earlier my custom CNN architecture was not really good, if anything, the learning process was too slow and inefficient. I thought of using transfer learning to solve the problem. I tried all these below architectures with ‘imagenet’ weights:
- ResNet50
- VGG16
- EfficientNet B0 — B5
Out of these efficientnet B4 was a better choice that gave good results with low train time.
-
The Loss function used was Cross-entropy for the most part, I also tried using Bi-Tempered Logistic loss (Google blog). I used label smoothing along with it because there were many noisy labels present in the training set. To learn more about label smoothing take a look at my code or go here.
-
I used the Adam optimizer with a starting learning rate of 0.001, I did not use any learning rate scheduler but used learning rate reducer as one of my callback functions.
-
At last the submissions were made with Soft-Voting ensembles of trained models.
After this, I got an LB score of 0.888, which was good but not enough to be competitive. So I used 5-Fold CV and did all the above steps all over again.
Results
I have tabulated all my results in the form of a markdown table have a look below :
Things I Tried but didn’t Work Out
- Froze all the layers of the pre-trained model and tried to only train the additional Dense layers, it did not work out, mostly because the dataset was not very resembling of imagenet data. (This is what I think and some kagglers as well).
- Tried to freeze the batch normalization layers to keep the original mean and standard deviation values, this messed up the model big time. I used custom mean and std values for the dataset, this did not help as well.
- Tried Nadam optimizer as well (RMSprop with Nesterov momentum), instead of Adam. This did not give any significant improvement over Adam.
- Tried Bi-Tempered Logistic Loss, this was most similar to Cross-Entropy, so I just went with CE.
- Test Time Augmentation (TTA), was tricky because many fellow competitors found this very useful and their accuracy increased. I did very few rotations and flips which did give me good results, but a little more heavy TTA saw a drop in the CV score. I decided to trust my CV and kept my TTA very light.
- This competition allowed using the 2019 cassava leaf dataset as well, But using it did not help at all.
Things I Learned for the First Time
Now comes the most important section, I jot down everything new learned in this wonderful journey of one month.
- First and foremost, Kaggle is all about small tweaks and experiments, PyTorch is very useful in this case, most of the kagglers use PyTorch. Even though TF2 is prominent in the industry, it’s really tough to use it in kaggle experiments. There aren’t many implementations in TF of new research papers as many as there are in PyTorch. (I have started learning PyTorch for this very reason)
- I have learned the basics of using the TPU’s provided which boost the training speed significantly.
- I learned to use the mixed-precision training policy which can reduce train times significantly.
- This was my first time using albumentations for augmentations, normally I use the in-built image data generator. It is very powerful and easy to use. I learned about label smoothing and pseudo labeling to tackle the noisy labels in the competition.
- Through this competition I came to know about efficientnets, these are very interesting and now SOTA CNN architectures. There was a paper release of NFnets from the deepmind team, they remove batch normalization layers altogether, which seems very interesting but unfortunately, I was unable to try them out with this competition.
- There is no doubt I learned so many coding techniques from many kaggle notebooks and discussion threads that I can’t even keep track of. Thanks for that guys.
- I knew about simple voting ensembling, but I learned about soft-voting ensembling where you add up all probability values and then take an average rather than choosing the most predicted class. (This came in really handy).
- I learned the importance of logging the results of your experiments, next time I will try out Neptune or any similar service. I was really disorganized at the beginning that made my further experiments hell. Organize your experiments and save several hours of hassle.
- I learned that in Kaggle trusting your CV score is as important as your Public LB score because after the competition the shakeup might really take a toll on you, I have seen people fall from 3rd place to 30 and 1000+ place to 150 as well. The model needs to have stability, rather than overfitting to the public test set.
- I looked into CutMixup paper as well, it was good but I did not get a chance to use it in my experiments.
- The trick to juicing out every ounce of accuracy from every model is to ensemble them all, I found out at the end of the competition that people were using 20–30 models to the ensemble to get to that top spot.
- I found a new way to clear the TF variables using tensorflow.keras.backend.clear_session(),
- Kaggle is a very good place to learn new things in this field. Ask any question, however naive it may be someone will answer and help you out for sure.
Conclusion
This competition added so much to my knowledgebase. I think I would have done better if I had a good team for this challenge, but it is what it is. Below you can find all the kernel links:
- Full organized case study: Kernel 1
- Random code that I did without recording any results: Kernel 2
- I have added Streamlit sharing support to deploy this model. Go here to test it out yourself.
- All the code and other things can be found in this Github repository.
If you have any questions use the comment box below. Cheers!😀